
Hiện nay, chúng ta đang gặp vấn đề về lưu trữ một lượng dữ liệu quá lớn: dữ liệu được tạo ra trong 2 năm gần đây lại nhiều hơn tất cả dữ liệu đã có trước đó [1]. Mọi thứ từ các bức ảnh, các bài báo cho đến các video trên Youtube, lượng dữ liệu này có thể đạt đến 44 ngàn tỉ GB đến năm 2020, gấp mười lần năm 2013. Nếu sử dụng bộ nhớ flash để lưu trữ thì nhà sản xuất cần đến 107 đến 108 kg tấm silicon [2].
DNA là một khả năng rất lớn cho việc lưu trữ vì khả năng mã hóa cho một lượng rất lớn dữ liệu, thời gian lưu trữ lâu dài [3]. Nếu mật độ lưu trữ của hệ thống bộ nhớ DNA cao, tất cả thông tin trên thế giới (cần khoảng 1022 bit), được chứa trong một hộp kích thước 10 x 10 x 10 cm3, nặng khoảng 1 kg. Thông tin trong DNA có thể lưu trữ đến 2,000 năm (10oC) đến 2,000,000 năm (-18o). Bên cạnh đó, chúng có thể được tái chế, sử dụng lại khi hủy các liên kết cũ giữa các nucleotide và hình thành những liên kết mới [2].
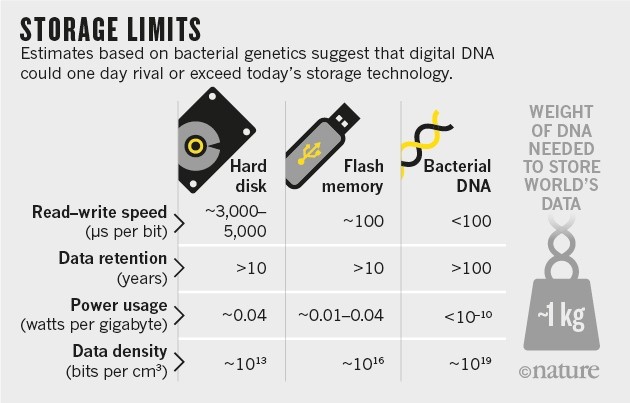
So sánh khả năng lưu trữ của DNA so với các hệ thống khác [4]
Một trong những khó khăn lớn khi lưu trữ trên DNA là sự khó khăn khi tổng hợp một đoạn trình tự dài không có khuôn ban đầu (de novo) thành một trình tự chính xác cực kì cao[3]. Vì thế nhiều nhà khoa học tiếp cận bằng cách tổng hợp nhiều đoạn oligo ngắn hơn. Tuy nhiên, việc mã hóa của DNA có một số giới hạn. Thứ nhất, không phải khả năng tạo ra tất cả trình tự DNA là như nhau. Có một số khó khăn và dễ bị lỗi khi tổng hợp các trình tự có tỉ lệ G-C cao hoặc một đoạn homopolymer (ví dụ AAAAAA...). Thứ hai, tổng hợp các đoạn oligo, phản ứng PCR và sự phân rã của DNA trong quá trình lưu trữ làm thay đổi số lượng các đoạn oligo. Điều này có thể làm mất một số đoạn và làm quá trình giải mã không thực hiện được. Ngoài ra, các oligo cần phải được sắp xếp theo thứ tự và phải có cách để tìm tìm thứ tự của chúng. Vì nếu không thể sắp xếp chúng theo thứ tự ban đầu thì không thể lưu trữ được dữ liệu [5].
Người đầu tiên có chuyển mã nhị phân 0, 1 thành 4 loại nucleotide là Joe Davis, một nhà nghệ thuật, vào năm 1988 với sự hợp tác với những nhà nghiên cứu từ Harvard. Trình tự DNA, được chèn vào E. coli chỉ mã hóa 35 bit [4]. Năm 2012, nhóm nghiên cứu của George Church về gene ở Đại học Harvard viết mã một quyển sách 52.000 từ trong vài nghìn đoạn DNA đã được thiết kế sẵn (snippet) [1]. Sử dụng bốn kí tự A, G, T, C để mã hóa cho các số 0, 1 của dữ liệu số, trong đó A, C mã hóa cho 0; G, T mã hóa cho 1. Sự linh hoạt này giúp tránh khỏi vấn đề đọc sai mã khi tỉ lệ G-C cao hay lặp lại một nucleotide. Họ không có hệ thống sửa sai, thay thế bằng cách tạo ra nhiều bản sao của một đoạn. Vì thế, sau khi tổng hợp Church và cộng sự đã phát hiện 22 lỗi – quá nhiều cho việc lưu trữ chính xác dữ liệu [4].
Sau đó, nhóm nghiên cứu của Goldman và Birney cũng sử dụng các đoạn oligo DNA và để tránh những lỗi, họ sử dụng nhiều hệ thống phức tạp. Một trong số đó là thay vì sử dụng mã nhị phân 0, 1 họ sử dụng mã tam phân 0, 1, 2. Bằng cách sử dụng các đoạn trùng lặp dài 100 cặp nucleotide, và mỗi đoạn có 4 bản sao để đảm bảo xác định và có thể sửa lỗi. Tuy nhiên họ vẫn sai 2 trong 25 trình tự [4].

DNA có thể trở thành phương tiện lưu trữ dữ liệu trong tương lai
Nhóm của Erlich và Yaniv gần đây công bố một cách tiếp cận khác. Dữ liệu được chuyển thành mã nhị phân, nén trong một file lớn và chia thành nhiều phần nhỏ. Họ phát triển một thuật toán là “DNA foutain”, đóng gói dữ liệu một cách ngẫu nhiên tạo thành những đơn vị gọi là “droplet”, từ đó họ thêm những thẻ nhận biết để sắp xếp các đoạn theo đúng trình tự. Kế tiếp, mã nhị phân được chuyển thành trình tự DNA bằng cách thay thế (00,01,10,11) lần lượt thành (A, C, G, T). Sau đó, các đoạn DNA này được kiểm tra xem có tỉ lệ G-C cao hay có đoạn homopolymer không. Trong nghiên cứu này, họ đã tổng hợp 72,000 chuỗi DNA, mỗi chuỗi có kích thước 200 nucleotide. Họ đã thành công khi mã hóa và giải mã 2.14 Mbyte dữ liệu và không có lỗi nào [5].
Một yếu tố khác đó là giá của việc tổng hợp DNA. Gần đây, giá của đọc mã DNA và viết mã tương ứng là 10-7 và 10-4 USD cho 1 bit. Giá của giải trình tự DNA đã giảm từ 0.1 xuống 10-7 US$ cho 1 bit trong 10 năm [2]. Kosuri và Erlich cho rằng cách tiếp cận của họ đưa phù hợp với những dữ liệu lớn vì nó có giá khoảng 7000$ để tổng hợp 2 Mb và 2000 USD để đọc nó [1]. Các thuật toán và phương pháp tiếp cận trong tương lai có thể sẽ giảm giá thành của việc tạo DNA lưu trữ cũng như thời gian để đọc và tổng hợp nó đi rất nhiều.
Hiện tại, vẫn có rất nhiều nghiên cứu của các tác giả khác về lĩnh vực này vì khả năng lưu trữ của DNA rất cao. Đây có thể là giải pháp tốt nhất cho việc lưu trữ lượng dữ liệu khổng lồ của thế giới.
Tác giả: Võ Thị Hạnh Đan (Đại học Khoa học Tự nhiên TP. HCM)
Tài liệu tham khảo:
1. Service, R., DNA could store all of the world's data in one room. Science, 2017.
2. Zhirnov, V., et al., Nucleic acid memory. Nat Mater, 2016. 15(4): p. 366-370.
4. Extance, A., How DNA could store all the world’s data. Nature, 2016. 537: p. 22-24.
5. Erlich, Y. and D. Zielinski, Capacity-approaching DNA storage. bioRxiv, 2016.

